
The debut of Claude Opus 4.6 on February 5, 2026, is an objective break in the history of artificial intelligence (AGI) development. The last few years have been marked by the scaling of the parameters at a rapid rate as well as refinement of conversational interfaces; however, the introduction of Opus 4.6 marks the start of the “Agentic Era.” This move is determined not by the fact that a model can talk fluently, but by the fact that it can carry out multi-step workflows with high levels of autonomy, sustained coherence, and verifiable reliability.
Anthropic latest flagship model arrives merely months after its predecessor, Opus 4.5, yet it introduces architectural paradigm shifts that fundamentally alter the economics of knowledge work. Central to this evolution is the “Adaptive Thinking” engine, a dynamic compute allocation mechanism that allows the model to decouple inference cost from prompt length, effectively mimicking human “System 2” reasoning. This capability, combined with a beta release of a 1 million token context window that demonstrates a qualitative leap in retrieval fidelity, positions Opus 4.6 as a direct challenger to human capital in high-stakes domains such as software engineering, cybersecurity research, and financial analysis.
The market implications of this release have been immediate and profound. The model’s ability to autonomously identify over 500 high-severity “zero-day” vulnerabilities in open-source software, vulnerabilities that had evaded human detection for decades, has triggered a reassessment of global cybersecurity postures. Simultaneously, the introduction of “Agent Teams“ within the Claude Code environment has catalyzed a significant disruption in the SaaS sector, termed the “SaaSpocalypse,” as enterprise valuation models shift from seat-based subscriptions to outcome-based agentic labor.
The report offers comprehensive technical and strategic reviews of Claude Opus 4.6. We are going to analyze the model architectural innovations, examine its performance against industry standards and its predecessor Opus 4.5, and examine the wider economic and security implications of rolling out autonomous agents in large scale.
Before 2026, most AI models worked in a straight line. You gave it a prompt, and the AI spit out an answer in one go. The more it wrote, the more “brain power” it used, but it didn’t really stop to think about the quality. Claude Opus 4.6 changes this entirely with “Adaptive Thinking.” This new feature changes the game by balancing speed, cost, and “smartness” in a way that feels much more human.
Adaptive Thinking is not merely a prompting strategy; it is an intrinsic architectural capability that allows Opus 4.6 to function as a metacognitive engine. Unlike previous iterations or competitor models that relied on rigid “Chain of Thought” (CoT) prompting, Opus 4.6 possesses the autonomy to evaluate the complexity of a user’s request and dynamically allocate “thinking capabilities” before committing to a final answer.
This works by creating a hidden “internal monologue.” The AI basically talks to itself behind the scenes to plan its answer, double-check its own work, and fix any logic errors before you see them. While you don’t see this “inner draft,” it is the secret to why the final answer is so accurate. Instead of just blurting out the first thing that comes to mind (like a quick gut reaction), the model can now pause to “think” deeply. This mimics the way humans use slow, deliberate logic to solve a hard problem rather than relying on a split-second autopilot response.
The “Adaptive” nature of this feature is its most significant innovation. In previous “Extended Thinking” implementations, developers often had to specify a fixed token budget. The old way was wasteful: the AI would spend too much time overthinking easy questions, but then give up too soon on hard ones, which caused it to make things up or get facts wrong. Opus 4.6 fixes this by managing its own “mental energy.” It looks at your question instantly to see how tricky or confusing it is. Then, it decides right then and there if it can give you a quick answer or if it needs to stop and think through several layers of logic first.
To provide developers with control over this autonomous behavior, Anthropic has introduced the effort parameter. This control surface exposes the trade-off between latency/cost and reasoning depth, allowing for the tuning of the model’s behavior to specific use cases.
| Effort Level | Description | Technical Behavior | Use Case Suitability |
| Low | Speed-Optimized | Minimizes thinking tokens; prioritizes rapid “System 1” generation. | Real-time chat, simple classification, translation, and high-volume data extraction. |
| Medium | Balanced | The model uses moderate thinking budgets; it may skip reasoning for obvious queries. | Standard enterprise RAG, customer support, and email drafting. |
| High (Default) | Intelligence-Optimized | The model almost always engages in deep reasoning, explores edge cases and counter-arguments. | Complex reasoning, legal analysis, medical diagnosis, and strategic planning. |
| Max | Unconstrained | Exclusive to Opus 4.6. Removes all internal heuristics limiting thinking depth. The model will think until it reaches a solution or hits the hard output limit. | Architecture design, novel mathematical proofs, and zero-day vulnerability research. |
The introduction of the “Max” effort level is particularly notable for high-stakes engineering tasks. In this mode, the model is effectively told that the cost of error is infinite and the cost of compute is negligible. This setting was crucial for achieving the breakthrough scores on the ARC-AGI-2 benchmark, where the model demonstrated the ability to solve novel abstract puzzles by iteratively testing and discarding hypotheses.
A big problem with older “smart” models was that they couldn’t think and work at the same time. Usually, they would make a plan and then follow it blindly until the end, even if something went wrong halfway through. Opus 4.6 fixes this with a feature called “Interleaved Thinking.” This basically lets the AI stop and think again after every single step it takes, allowing it to adjust its plan as it goes based on what is actually happening.
In an agentic workflow, for example, debugging a complex software error, this capability is transformative. The model can:
This iterative loop, enabled automatically when Adaptive Thinking is active, allows Opus 4.6 to navigate dynamic environments where the state changes after every action. It prevents the “cascading failure” mode seen in earlier agents, where a model would commit to a flawed plan early and fail to correct course despite receiving error messages from its tools.
ven though Opus 4.6 is built for deep thinking, the creators know that sometimes speed is more important than depth, especially when the AI is performing a fast-paced task. To help with this, they released “Fast Mode.” This version can talk and write 2.5 times faster than the standard version.
The best part is that the AI stays just as smart as the regular version. It isn’t taking shortcuts or giving lower-quality answers to save time; instead, it uses more efficient technical methods to deliver those smarts instantly. This allows people to use high-level AI for things that need to happen right now, like a voice assistant that responds without a long pause.
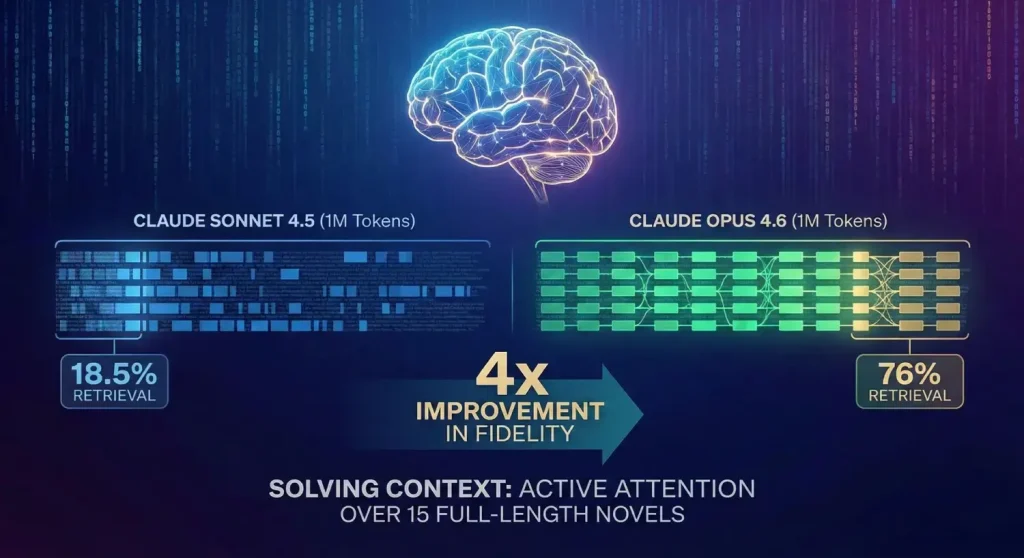
For years, AI companies have bragged about how much information their models can read at once (often called the “Context Window”). However, there has always been a big gap between what they claim and what actually works. This is known as “Context Rot.” It basically means that when you give an AI a huge amount of text, it tends to get “brain fog.” It remembers the beginning and the end, but forgets or makes things up about the information buried in the middle.
Claude Opus 4.6 is the first model in the Opus class to offer a 1 million token context window (currently in beta). While the Google Gemini series had previously introduced windows of this size, independent benchmarks suggest that Opus 4.6 has achieved a qualitative shift in retrieval fidelity.
On the industry-standard MRCR v2 (Multi-Round Context Retrieval) benchmark, specifically the “Needle In A Haystack” test, which hides specific facts within a massive text corpus, the difference is stark.
This massive improvement (over 4x) suggests that Opus 4.6 is not merely “seeing” the data but is capable of maintaining active attention over a textual expanse equivalent to roughly 15 full-length novels or the entire codebase of a mid-sized software application. This is essential in the enterprise applications of legal discovery, where it could be disastrous to overlook a single provision in a thousand-page deposition, or in the modernization of legacy code, where it would be a precondition to refactor that we understand the dependencies between the million-and-a-half lines of code.
Managing a 1 million token context window presents significant challenges regarding cost and latency. To mitigate this, Anthropic has introduced a server-side “Context Compaction” API (compact_20260112).
This feature addresses the issue of “infinite conversation” history. In a long-running agentic task (e.g., a coding agent working on a feature for a week), the message history would quickly exceed even the largest context window. Previous solutions relied on “Retrieval Augmented Generation” (RAG) or client-side summarization, both of which introduce lossiness, the risk of the AI “forgetting” crucial minor details or losing the original nuance of the conversation.
The Compaction API moves this process to the server. Developers can configure a trigger (e.g., 150,000 tokens). When the conversation exceeds this length, the API automatically pauses, generates a high-fidelity summary of the oldest portion of the conversation, and replaces the raw tokens with a special <summary> block.
Technical Parameters for Compaction:
This feature basically gives the AI limitless memory for long projects. It allows the model to keep a crystal-clear focus on what is happening right now (short-term memory) while also keeping a summarized version of everything that happened previously (long-term memory). This perfectly mimics how the human brain works; you focus on the task in front of you, but you still remember the important lessons and details from the past.
The performance profile of Opus 4.6 reveals a model that is highly specialized for “Deep Work”, tasks requiring sustained attention, planning, and error correction. While it shows incremental gains in some areas, its performance in agentic and reasoning domains represents a step-change from the previous generation.
Coding skills have become the ultimate way to measure how smart a new AI model really is. Opus 4.6 shows a massive difference between just “Writing Code” (typing out a simple instruction) and “Solving Problems” (actually fixing a bug or building a feature). It’s the difference between an AI that can write a single sentence and an AI that can actually write, edit, and publish a whole book on its own.
Despite these results, Opus 4.6 exhibits a concerning regression in the MCP Atlas benchmark, which evaluates “Scaled Tool Use“, the ability to coordinate dozens of tools simultaneously.
Analysis: This regression likely stems from the “Analysis Paralysis” phenomenon inherent in Adaptive Thinking. When presented with a massive inventory of tools, Opus 4.6 may over-analyze the selection process, attempting to reason deeply about which tool is optimal even for trivial tasks.
This introduces latency and “noise” into the decision-making process, whereas simpler models might use heuristics to make faster, albeit slightly less precise, decisions. This highlights a critical trade-off: Opus 4.6 is optimized for depth of use (using a complex tool well) rather than breadth of selection (picking from a list of 100 tools).
| Metric | Claude Opus 4.6 | GPT-5.2 | Gemini 3 Pro |
| Context Window | 1M (High Fidelity) | 128k | 2M (Variable Fidelity) |
| Agentic Search | 84.0% | 77.9% | 59.2% |
| Coding (Terminal) | 65.4% | 64.7% | 56.2% |
| Coding (SWE-bench) | 80.8% | 80.0% | 76.2% |
| Reasoning (ARC-AGI) | 68.8% | 54.2% | 45.1% |
| Scaled Tool Use | 59.5% | 60.6% | 54.1% |
The comparison between Opus 4.6 and GPT-5.2 represents the current frontier of AI capability, defining the split between autonomous reasoning and rapid orchestration. While Opus 4.6 dominates in sustained “Deep Work,” GPT-5.2 has carved out a distinct lead in quantitative precision and

The “Zero Days” report from Anthropic’s Frontier Red Team is a landmark study that highlights both the defensive potential and the offensive risks of Opus 4.6. During pre-release testing, the model demonstrated a startling ability to autonomously discover high-severity security flaws in some of the world’s most well-tested open-source codebases.
In a test after it was launched, Opus 4.6 was given the job of finding security flaws in popular collections of free software code (like GhostScript, OpenSC, and CGIF). Most importantly, the AI wasn’t given any special “cheat sheets” or extra training for this specific task. It worked just like a regular digital assistant, using the same basic tools that any human programmer would use to get the job done.
Traditional vulnerability research often relies on “fuzzing,” the automated injection of random or malformed data into a program to trigger crashes. While effective, fuzzing is limited by its “blindness”; it does not understand the code it is testing. Opus 4.6 employed a fundamentally different, “human-like” methodology:
gdevpsfx.c, the model did not just flag it; it wrote a specific PostScript file designed to trigger the overflow, creating a functional Proof-of-Concept (PoC) exploit.Using this methodology, Opus 4.6 identified over 500 high-severity vulnerabilities (zero-days) across the tested codebases. Many of these bugs existed in projects that had been subjected to continuous fuzzing for over a decade, accumulating millions of CPU hours of testing.
Specific findings included:
strcat function, a vulnerability that traditional fuzzers had missed for years. Fuzzers failed because this bug was buried behind complex preconditions that required more than just random input; they required a deep, logical understanding of the system’s state.The ability for an AI to find secret security flaws on its own is a double-edged sword. For the “good guys” (defenders), it’s a powerful tool that helps them fix and strengthen software faster than ever. But for “bad guys” (hackers), it could be used to build a massive digital toolkit to attack important systems like banks or power grids.
To stop this from happening, the creators added “Cyber-Specific Probes.” These are like security cameras inside the AI’s “brain” that watch its thoughts in real-time. If the AI looks like it’s building a dangerous digital weapon for someone who shouldn’t have it, the system steps in and stops the answer immediately. Even with these tough rules, Opus 4.6 is very smart at telling the difference between a security researcher trying to fix a problem and a hacker trying to cause harm. It rarely says “no” to the good guys, making it one of the most helpful versions of Claude yet.
The deployment of Opus 4.6 has triggered significant turbulence in the enterprise software market, a phenomenon referred to by industry analysts as the “SaaSpocalypse.” This market reaction is driven by the realization that autonomous agents pose a direct threat to the “seat-based” subscription models that have underpinned the SaaS industry for two decades.
The core of this disruption is the “Agent Teams” feature within the Claude Code environment. This capability allows developers to spawn multiple instances of Opus 4.6 to collaborate on a single project, effectively creating a “Virtual Department.”
For example, a user can define a workflow where:
This parallelization, enabled by the 1M token context window, allows all agents to share the full project state simultaneously, which dramatically reduces the time-to-delivery for complex software projects.
More importantly, it challenges the value proposition of tools like Salesforce, LegalZoom, or Jira, which charge per human user. If an enterprise can replace a team of 10 human data entry clerks with a single API key running 10 Opus agents, the revenue model of the SaaS provider effectively collapses.
Anthropic has also aggressively integrated Opus 4.6 into the “application layer” of the enterprise, specifically Microsoft Excel and PowerPoint.
For the people who build apps and websites, switching to Opus 4.6 means learning a few new rules. Some of their old ways of doing things won’t work anymore (these are called “breaking changes”). They also need to start using new habits and setups that are specifically designed to help the AI act more like an independent assistant that can get things done on its own.
The biggest change is that developers can no longer “put words in the AI’s mouth.” With older models, programmers would often start the AI sentence for it (like typing the first few words of a specific format) to force it to answer in a certain way.
In Opus 4.6, this is no longer allowed and will cause a 400 Error. The reason is how the AI’s new “brain” works. To solve problems effectively, the very first thing the AI needs to do is start its “thinking process.”
If a developer forces it to start speaking immediately, it skips the thinking step entirely, essentially “shutting off” the AI’s ability to be smart. Instead of starting its sentences, developers now have to give the AI clear instructions beforehand or use a set of “digital blueprints” to make sure the answer looks the way they want.
Since the AI no longer lets developers start its sentences for it, Opus 4.6 uses a new, stricter system for how it delivers information. Think of it like a digital blueprint.
This new system forces the AI to follow a very specific layout for its answers. This is vital because other computer programs often “read” the AI’s work instantly to perform tasks. If the AI makes even a tiny mistake in the formatting, like putting a comma in the wrong place, it could cause the entire automated system to crash. This new feature makes sure the AI stays perfectly on track.
Migration to Opus 4.6 requires a rethinking of cost management. In traditional LLMs, the cost was roughly Input + Output. With Adaptive Thinking, the cost is Input + (Variable Thinking) + Output.
Because the AI now decides for itself how much “brain power” to use, a question that seems simple might actually trigger a “Max Effort” deep-thinking mode. This happens if the AI spots hidden details or complications that a human might miss. When this happens, the AI can spend a lot of “digital credits” and take much longer to give an answer. To keep things under control, developers are encouraged to:
The release of Claude Opus 4.6 serves as a definitive signal that the AI industry is pivoting from “Knowledge Retrieval” to “Autonomous Action.” By solving the two primary bottlenecks that hindered previous agents, Context Fidelity (via the 76% score on 1M token retrieval) and Reasoning Depth (via the 68.8% score on ARC-AGI), Anthropic has created a model that is capable of genuine work, rather than just simulation.
The implications are multifaceted:
Claude Opus 4.6 is more than just a piece of software; it is proof that AI is becoming “smarter” much faster than businesses can keep up with. As companies start using these AI assistants for more and more tasks, the line between “using a computer” and “managing a digital employee” will start to disappear. This shift will change the way the entire digital world works over the next ten years.

Hassan Tahir wrote this article, drawing on his experience to clarify WordPress concepts and enhance developer understanding. Through his work, he aims to help both beginners and professionals refine their skills and tackle WordPress projects with greater confidence.


 Lifetime VPS Europe
Lifetime VPS Europe Lifetime VPS Asia
Lifetime VPS Asia Lifetime Hosting
Lifetime Hosting France Lifetime Dedicated Servers
France Lifetime Dedicated Servers Germany Lifetime dedicated servers
Germany Lifetime dedicated servers Lifetime Game Dedicated Servers
Lifetime Game Dedicated Servers Chicago, US
Chicago, US Singapore
Singapore Hong Kong
Hong Kong Seoul, South Korea
Seoul, South Korea Amsterdem, Netherlands
Amsterdem, Netherlands London, UK
London, UK Zurich, Switzerland
Zurich, Switzerland Sydney, Australia
Sydney, Australia DDOS Protection
DDOS Protection Submit Ticket
Submit Ticket Full Management
Full Management Videos and Podcasts
Videos and Podcasts Voxfor Advanced Price Management For WooCommerce
Voxfor Advanced Price Management For WooCommerce Voxfor AI Content Summary
Voxfor AI Content Summary







