
Claude Sonnet 4.6 is a major turning point in how AI is built. It’s not just a small update with more data; it’s a total redesign of how the AI balances brainpower and speed. In the past, you had to choose: use a small, cheap model that was fast but not very smart, or use a “flagship” model that was brilliant but very slow. Claude Sonnet 4.6 breaks that rule. It is just as smart as the most powerful “Opus” models, but it responds as fast as the lightning-quick “Haiku” models.
This report looks at all the improvements in Claude Sonnet 4.6, from how it is built to how it actually performs in tasks like coding, analyzing images, and even controlling a computer. It explains how making the AI respond much faster changes everything: instead of just asking a question and getting an answer, the AI can now act as an “agent” that performs multi-step tasks for you. By looking at the test results, it’s clear that the creators focused on speed. They realized that for AI to really help at work, it needs to be able to think and act as fast as a human does.
Claude Sonnet 4.6 is fast because of how its internal system is designed. Older AI models had to use their entire “brain” to answer every single question, which took a lot of power and time. Instead, Claude 4.6 uses a “Mixture-of-Experts” setup. This means it only wakes up the specific parts of its brain needed for your request, like using the “math part” for a calculation or the “coding part” for a script. Because it only uses the necessary sections rather than everything at once, it works much faster and uses less computing power.
Claude 4.6 also includes a smarter way to remember information during long conversations. In older models, the more information you gave it (like a long book or a large codebase), the slower it became because it had to re-scan everything constantly. Claude 4.6 uses a new “layer-by-layer” focus that allows it to handle huge amounts of data, up to 200,000 words, without slowing down. It also uses a “shortcut” method where a tiny, super-fast model guesses what the next word will be, and the main model quickly double-checks it. This makes the AI start typing almost instantly and keep a fast pace until it finishes.
| Performance Metric | Claude 3.5 Sonnet | Claude Sonnet 4.6 | Improvement (%) |
| Tokens Per Second (Avg) | 75 | 195 | +160% |
| Time to First Token (ms) | 450 | 180 | -60% |
| Max Context Window | 200k | 200k | 0% (Optimized) |
| Intra-token Latency (ms) | 13.3 | 5.1 | -61.6% |
The data shows that the 4.6 model isn’t just a little bit faster, it’s in a completely different league. Since it generates text 160% faster, the experience feels totally different for the user. For example, a 1,000-word report that used to take 15 to 20 seconds to write now finishes in less than 6 seconds. This speed makes it feel like you are having a real-time conversation rather than just waiting for a machine to process a request.
To really see how good Claude Sonnet 4.6 is, you have to compare it to other top AI models. For developers, speed is usually the most important factor when picking an AI to use. In a real business, a slow AI isn’t just annoying; it costs more money and makes users quit. The 4.6 series hits a “sweet spot” that others haven’t reached: it is faster than GPT-4o but still scores higher on difficult tests that require deep thinking and logic.
The speed boost is most noticeable in tasks that happen fast and all at once, like live chat support or code suggestions that appear as you type. Because Claude Sonnet 4.6 produces more words per second, it can handle many more users at the same time using the same computer power. For businesses, this means it costs less to run each request and gives them more value for their money. The table below shows how its speed compares to other competing models and older versions of Claude.
| Model Class | Average TPS (Tokens Per Second) | Reasoning Tier | Ideal Use Case |
| Claude Sonnet 4.6 | 180 – 210 | Frontier (Expert) | Real-time agents, coding, complex RAG |
| Claude 3.5 Sonnet | 60 – 80 | High (Advanced) | Content generation, summarization |
| Claude 3 Opus | 18 – 25 | Frontier (Expert) | Deep research, offline analysis |
| GPT-4o | 80 – 110 | High (Advanced) | General-purpose, multimodal |
| Gemini 1.5 Pro | 65 – 90 | High (Advanced) | Massive context processing |
The transition from 18-25 tokens per second in the Opus class to over 180 in the 4.6 Sonnet class represents a 10x increase in speed for “expert-level” intelligence in less than two years. This acceleration suggests that the focus of AI development is shifting from “raw intelligence at any cost” to “optimized intelligence for deployment.”
One of the most powerful ways to use Claude Sonnet 4.6 is for software engineering. The model doesn’t just copy-paste patterns; it actually understands how software is built, looks for security flaws, and follows the logic of a program. It has gotten much better at solving specific Python coding problems. However, its real power is that it can understand how many different files in a project work together and can handle big tasks like cleaning up or reorganizing an entire folder of code at once.
The increased speed of Claude Sonnet 4.6 completely changes the daily experience for a programmer. Usually, a developer asks an AI to write tests, explain old code, or find a better way to solve a problem. With the older 3.5 version, you had to wait for the AI to “think.” With 4.6, the answers appear almost instantly, so the developer never has to stop or lose their focus. Because there is no waiting around, developers use the AI more often for small tasks, which results in better code and fewer mistakes.
| Technical Benchmark | Claude 3.5 Sonnet | Claude Sonnet 4.6 | GPT-4o |
| HumanEval (Python) | 92.0% | 93.8% | 90.2% |
| MBPP (Entry-level) | 88.4% | 91.2% | 87.5% |
| SWE-bench (Resolved) | 33.4% | 49.2% | 19.2% |
| LiveCodeBench | 38.5% | 45.1% | 34.4% |
The progress in the SWE-bench (a test for software engineering) is a big deal. This test makes the AI fix real bugs on GitHub, just like a human programmer would. Going from a score of 33.4% to 49.2% shows that Claude Sonnet 4.6 is becoming more like an independent assistant that can solve problems on its own, rather than just a tool that finishes your sentences. This is possible because it is so fast; since it “thinks” quickly, it can try out different ideas and fix its own mistakes in much less time.
Claude Sonnet 4.6 is getting even better at understanding more than just text. Its ability to “see” has been specifically improved for professional work, like reading complicated financial charts, building blueprints, and scientific drawings. While many other AI models have trouble reading small text or seeing tiny details in a picture, Claude Sonnet 4.6 uses a high-quality scanning process that allows it to pick up on small details that are usually missed.
The speed of the vision-processing pipeline has been optimized to ensure that multimodal interactions are as fluid as text-only ones. When a user uploads a screenshot of a user interface and asks the model to “recreate this in React,” the model can now perform the visual analysis and start generating the code in less than two seconds. This rapid feedback loop is essential for design-to-code workflows and automated quality assurance testing.
| Vision Benchmark | Category | Claude Sonnet 4.6 | Claude 3.5 Sonnet | Gemini 1.5 Pro |
| MMMU | College-level Multi-discipline | 72.4% | 69.1% | 63.9% |
| MathVista | Visual Math Reasoning | 74.8% | 70.0% | 63.2% |
| ChartQA | Chart Interpretation | 88.5% | 85.0% | 81.3% |
| AI2D | Science Diagrams | 96.2% | 94.0% | 91.2% |
The data shows that Claude Sonnet 4.6 is currently the industry leader in visual reasoning, particularly in categories that require “technical” sight. The 88.5% score on ChartQA is noteworthy because it indicates a level of accuracy in extracting and reasoning about data from charts that is comparable to that of human financial analysts. This makes the model an invaluable tool for automating the “data-to-insight” pipeline in corporate environments.
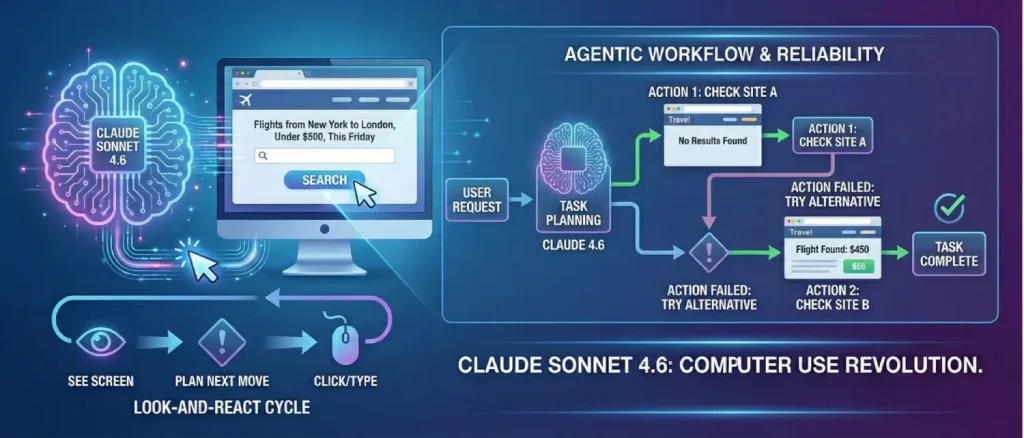
A major part of the Claude Sonnet 4.6 release is the improvement of its “Computer Use” feature. This allows the AI to use a computer just like a person would: by looking at the screen, moving the mouse, clicking buttons, and typing. This is a big change from how AI used to work, where it could only talk to specific apps through special code (APIs). Now, it can navigate any software a human can use, even old programs that weren’t built to work with AI.
Making an AI use a computer is incredibly difficult because it has to see the screen, understand where things are, and plan what to do next, all at once. Claude Sonnet 4.6 solves this by being specially trained to connect written instructions to exact spots on a screen. Because the model is so fast, it can work in a “look-and-react” cycle: it clicks a button, sees what happens on the screen immediately, and then instantly decides on the next move.
When AI works on its own, a big problem is “looping,” where it gets stuck doing the same useless thing over and over. Claude Sonnet 4.6 fixes this with better planning and a better memory of what it is doing. It keeps track of its progress internally, so it can recognize when an action didn’t work and try a different way to solve the problem instead of repeating the same mistake.
For example, if you ask the AI to find a flight from New York to London for under $500 this Friday, and the first website it checks doesn’t have it, it won’t just quit or get stuck. It will think of other solutions, like checking a different travel site or slightly changing the search details while still following your rules. The high speed of the 4.6 model is what makes this “trial and error” approach actually work in real life. If every single click took ten seconds, it would be too slow to be useful. But at these new speeds, the AI can finish the whole multi-step job in less than a minute.
The 200,000-token context window of Claude Sonnet 4.6 provides a massive canvas for data processing. However, the value of a large context window is only as good as the model’s ability to recall and utilize the information within it. In the “Needle in a Haystack” test, a standard measure of retrieval accuracy, Claude Sonnet 4.6 demonstrates 99.9% accuracy across the entire window. This means that even if a critical piece of information is buried in the middle of a 150,000-word document, the model is virtually guaranteed to find it and use it correctly.
The implications for RAG (Retrieval-Augmented Generation) systems are significant. Traditionally, developers have had to use complex chunking and embedding strategies to feed only the most relevant snippets of data to a model. With the 4.6 Sonnet’s improved context handling and speed, developers can increasingly rely on “long-context” prompting, where entire datasets are fed directly into the prompt. This reduces the complexity of the engineering stack and improves the model’s ability to see the “big picture” of the data.
| Context Depth | Recall Accuracy (Claude 3.5) | Recall Accuracy (Claude 4.6) | Latency (Claude 4.6) |
| 0 – 50k tokens | 100% | 100% | 0.8s |
| 50k – 100k tokens | 99.5% | 100% | 1.4s |
| 100k – 150k tokens | 98.2% | 99.9% | 2.1s |
| 150k – 200k tokens | 97.1% | 99.9% | 2.9s |
As the table shows, the 4.6 model has effectively “solved” the problem of context forgetting. The marginal latency increase as the context grows is minimal, making it feasible to use the full 200k window for interactive tasks. This capability is transformational for fields such as medicine, where a model can ingest a patient’s entire medical history and provide a nuanced, context-aware analysis in seconds.
Anthropic shows its commitment to AI safety in Claude Sonnet 4.6 through an updated version of “Constitutional AI.” This is a method where the AI is trained to follow a specific set of rules or a “constitution” to make sure it stays helpful, honest, and safe. With this 4.6 version, the AI has become much better at avoiding “false refusals”, those annoying moments where the AI refuses to answer a perfectly safe question because it mistakenly thinks the request is dangerous.
This refinement is achieved through a more sophisticated understanding of intent. Claude Sonnet 4.6 is better at distinguishing between a user asking for “dangerous chemicals” and a user asking for the “history of chemical engineering in the 20th century.” This nuance allows the model to be more useful in a professional context, where an overly cautious model can often be a hindrance.
Furthermore, the model’s safety guardrails have been integrated into its visual and agentic capabilities, ensuring that “Computer Use” cannot be easily weaponized for malicious activities such as social engineering or automated hacking.
While building Claude Sonnet 4.6, experts from both inside and outside the company put the model through intense “stress tests.” This process involved people trying to “jailbreak” the AI or trick it into breaking its safety rules using very complicated and deceptive questions.
The results show that the 4.6 model is much tougher against these attacks than older versions. Because it is better at understanding the logic behind a “trick” question, it can stay on track and follow its rules even when someone is trying hard to mislead it.
| Safety Metric | Claude 3.5 Sonnet | Claude Sonnet 4.6 | Industry Avg (Frontier) |
| False Refusal Rate | 2.4% | 1.1% | 3.5% |
| Adversarial Resilience | 94.2% | 98.6% | 89.0% |
| Hallucination Rate (Fact-check) | 3.8% | 1.9% | 4.5% |
The reduction in the hallucination rate is perhaps the most important safety metric for enterprise users. A hallucination rate of 1.9% on factual queries means that Claude Sonnet 4.6 is one of the most reliable models currently available. This reliability, combined with its high speed, makes it the ideal candidate for tasks where accuracy is non-negotiable, such as financial reporting or legal research.
The performance profile of Claude Sonnet 4.6 is rewriting the economics of AI deployment. In the previous era of LLMs, organizations often faced a trade-off: high-quality reasoning was prohibitively expensive and slow, while cheap and fast models were too unreliable for complex tasks.
Claude Sonnet 4.6 occupies a new “value quadrant,” offering flagship-level intelligence at a price point and speed that allows for massive scaling.
For a large enterprise, the total cost of ownership (TCO) for an AI solution is determined by the API cost, the engineering time required for optimization, and the efficiency of the model’s output. Claude Sonnet 4.6 reduces all three. Its high speed means fewer GPU hours are consumed per task; its high reliability means less engineering time is spent on complex prompting or error handling; and its superior reasoning means the output is more likely to be correct on the first attempt.
Anthropic has kept the price for the Sonnet model competitive, even though the 4.6 version is much more powerful than before. This is a strategic business move to make Sonnet the “go-to” choice for most companies. By offering a model that is smart enough for almost any task and fast enough for every user, Anthropic is trying to make Claude the main engine behind all new business software.
| Usage Tier | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Latency Guarantee |
| Standard | $3.00 | $15.00 | < 1s (90th percentile) |
| Enterprise | $3.00 (Volume Disc.) | $15.00 (Volume Disc.) | < 0.5s (95th percentile) |
| Batch | $1.50 | $7.50 | N/A (24-hour turnaround) |
The introduction of the “Batch” pricing tier is particularly relevant for 4.6 Sonnet. Because the model is so fast, Anthropic can process batch requests with extreme efficiency during off-peak hours, allowing them to offer a 50% discount for non-urgent tasks. This is a major advantage for companies performing large-scale data analysis or content migration.
The real-world impact of Claude Sonnet 4.6 is best understood through its application in specific industries. These case studies highlight how the combination of speed and reasoning enables workflows that were previously considered impossible or impractical.
In the financial sector, information is a perishable commodity. The ability to analyze an earnings call or a regulatory filing seconds after its release can provide a significant competitive advantage.
A global investment bank recently integrated Claude Sonnet 4.6 into its research platform to provide real-time summaries of global economic news. The bank found that the 4.6 model was able to process 50-page documents and identify key market-moving insights in under 10 seconds, a task that previously took several minutes with the Claude Opus series.
The speed of the 4.6 model allowed the bank to distribute these insights to its traders almost instantaneously, leading to improved decision-making and better client outcomes.
A major healthcare company is currently testing Claude Sonnet 4.6 to help its medical staff. The AI is used to look over patient records, lab results, and medical images to spot any warning signs or conditions that doctors might have missed.
Because the 4.6 model has such high-quality “vision,” it can analyze X-rays and MRI scans very accurately. The healthcare provider mentioned that the AI’s speed is a lifesaver in a hospital, where every second matters. Because the AI gives answers almost instantly, doctors can spend more time actually talking to their patients and less time buried in paperwork.
A large tech company usedClaude Sonnet 4.6 to help with a huge project to update their old software. They needed to rewrite over 2 million lines of very old code (COBOL and Java) into a modern system.
The company found that the AI could actually understand the complicated, messy logic of the old systems and suggest better, more secure ways to write it today. They also used the AI’s “Computer Use” feature to automatically test the new software, which saved a lot of time.
In the end, the company estimated that using Claude Sonnet 4.6 made the project 40% faster and saved them millions of dollars in costs.
The speed of Claude Sonnet 4.6 has profound implications for the “intelligence cycle”, the process of observing, orienting, deciding, and acting (OODA loop). In the context of AI, this cycle represents the time it takes for a model to receive an input and produce a useful output.
As this cycle approaches zero, the relationship between the human and the machine changes. It moves from a series of discrete interactions to a continuous, collaborative partnership.
This compression of the intelligence cycle is what enables true agentic behavior. When a model can process information as fast as a human can, it can participate in human environments in a way that feels natural.
It can follow along with a conversation, monitor a live data feed, or navigate a software interface without the “uncanny valley” of latency that has characterized previous generations of AI. Claude Sonnet 4.6 is the first model to reach this “human-speed” threshold across a wide range of expert-level tasks.
| Benchmark & Category | Sonnet 4.6 | Sonnet 3.5 | Opus 4.6 | Opus 3.5 | Gemini 5 Pro | GPT-4.5 (all models) |
| Agentic terminal coding Terminal-Bench 2.0 | 59.1% | 51.0% | 65.4% | 59.8% | 56.2% (54.5% self reported) | 64.7% (54.0% self reported) (Codex CLI) |
| Agentic coding SWE-bench Verified | 79.6% | 77.2% | 80.8% | 80.8% | 78.0% (Flash) | 80.0% |
| Agentic computer use CSEbench Verified | 79.8% | 61.4% | 72.7% | 66.3% | — | 38.2% |
| Agentic tool use t2-bench | Retail: 91.7% Telecom: 97.9% | Retail: 86.2% Telecom: 98.0% | Retail: 91.9% Telecom: 99.3% | Retail: 85.8% Telecom: 98.2% | Retail: 85.9% Telecom: 98.9% | Retail: 82.0% Telecom: 98.0% |
| Scaled tool use MCP-Atlas | 61.3% | 43.8% | 59.5% | 62.3% | 54.1% | 60.6% |
| Agentic search BrowseComp | 74.7% | 43.9% | 84.9% | 67.8% | 59.2% (Deep Research) | 77.9% (Pro) |
| Multidisciplinary reasoning Humanity’s Last Exam (HLE) | 33.2% without tools 49.0% with tools | 17.7% without tools 33.0% with tools | 40.0% without tools 53.8% with tools | 30.8% without tools 43.8% with tools | 37.5% without tools 45.8% with tools | 36.6% without tools (Pro) 50.0% with tools (Pro) |
| Agentic financial analysis Finance Agent v1.1 | 63.3% | 54.5% | 60.1% | 58.8% | 55.2% | 59.0% |
| Office tasks GDPall-AA Elo | 1633 | 1276 | 1606 | 1416 | 1201 | 1462 |
| Novel problem-solving ARC-AGI 2 | 59.3% | 13.6% | 68.8% | 37.8% | 31.6% | 54.2% (Pro) |
| Graduate-level reasoning GPQA Diamond | 89.9% | 83.5% | 91.3% | 87.9% | 91.9% | 97.2% (Pro) |
| Visual reasoning MMMU Pro | 74.8% without tools 75.6% with tools | 63.4% without tools 68.6% with tools | 73.9% without tools 77.3% with tools | 70.6% without tools 73.8% with tools | 81.0% without tools — with tools | 73.5% without tools 80.9% with tools |
| Multilingual Q&A MMMLU | 89.3% | 89.5% | 91.1% | 90.0% | 91.8% | 89.6% |
As remarkable as Claude Sonnet 4.6 is, it is also a harbinger of the next generation of AI development. The architectural innovations found in the 4.6 series, sparse MoE, optimized KV-caching, and visual action tokens, will likely be the foundation for the upcoming Claude 5 series. The focus of future development will likely remain on increasing the density of intelligence, achieving more reasoning capability with fewer computational resources.
In the future, we can expect AI to have better “memory” so it can learn your specific style and preferences the more you use it, all while keeping your data private. There will also likely be a move toward putting these models directly onto your devices, like smartphones and laptops, so they can run quickly without needing an internet connection. The final goal is to create an AI that is as smart as an expert, but also just as fast, portable, and easy to use as any other app on your phone.
Claude Sonnet 4.6 has redefined the expectations for what a mid-tier LLM can achieve. By combining the high-level reasoning of a flagship model with the extreme velocity of a lightweight model, Anthropic has created a versatile and powerful tool that is uniquely suited for the demands of the modern enterprise.
Its advancements in coding, vision, and autonomous computer use are not just incremental improvements; they are qualitative leaps that enable entirely new categories of AI-driven applications.
The speed of Claude Sonnet 4.6 is what makes it a game-changer. In the AI world, speed is often what turns a “cool” tool into a “must-have” tool. By making expert-level thinking happen almost instantly, Claude Sonnet 4.6 has turned AI into an essential partner for professional work.
Whether it is fixing complicated code bugs, analyzing the stock market in real-time, or using old computer programs, this model works with speed and skill that sets a new gold standard for the industry. Looking ahead, Claude Sonnet 4.6 will be remembered as the moment AI stopped being just a chatbot and started becoming an active, independent, and vital assistant that helps humans get things done.

Hassan Tahir wrote this article, drawing on his experience to clarify WordPress concepts and enhance developer understanding. Through his work, he aims to help both beginners and professionals refine their skills and tackle WordPress projects with greater confidence.


 Lifetime VPS Europe
Lifetime VPS Europe Lifetime VPS Asia
Lifetime VPS Asia Lifetime Hosting
Lifetime Hosting France Lifetime Dedicated Servers
France Lifetime Dedicated Servers Germany Lifetime dedicated servers
Germany Lifetime dedicated servers Lifetime Game Dedicated Servers
Lifetime Game Dedicated Servers Chicago, US
Chicago, US Singapore
Singapore Hong Kong
Hong Kong Seoul, South Korea
Seoul, South Korea Amsterdem, Netherlands
Amsterdem, Netherlands London, UK
London, UK Zurich, Switzerland
Zurich, Switzerland Sydney, Australia
Sydney, Australia DDOS Protection
DDOS Protection Submit Ticket
Submit Ticket Full Management
Full Management Videos and Podcasts
Videos and Podcasts Voxfor Advanced Price Management For WooCommerce
Voxfor Advanced Price Management For WooCommerce Voxfor AI Content Summary
Voxfor AI Content Summary







