
This has been achieved through an artificial intelligence system which has shown surprisingly ability to predict how people move based on body language and gaze direction, and other environmental cues in real time. The system does not just respond to movement but tries to predict the intentions of pedestrians crossing all that a person is about to do up to a second in advance. This strategy changes the autonomous vehicle safety from reactive to proactive instead of reactive.

Researchers fromTexas A&M and KAIST developed OmniPredict, a multimodal large language model. OmniPredict is a multimodal large language model developed by researchers of Texas A&M and KAUST and aimed at making self-driving cars safer. It is the first application of MLLM to predict pedestrian crossing intentions without task-specific fine-tuning to extend beyond its traditional vision-only counterparts that can only generalize to their training data.
OmniPredict functions based on four types of data inputs, including scene context images, local context images, bounding box coordinates, and ego-vehicle speed. Instead of a single sensor modality, the system integrates both the visual and the contextual data with the aim of classifying pedestrian behaviors like crossing, obstruction, overall activity, and the direction of gaze.
What distinguishes OmniPredict is its reliance on multimodal large language models proven effective in chatbots and image recognition. The system employs GPT-4o with instruction prompts designed to interpret driving environments with human-like reasoning.
The operational flow is straightforward: 16 previous frames predict 30 frames, approximately one second ahead in real-time driving conditions. This temporal window is critical for autonomous vehicles to execute evasive maneuvers before an accident occurs.
The performance metrics are significant. OmniPredict achieved 67% JAAD accuracy without any task-specific training or retraining on new data. This represents 17.5% improvement over GPT-4V-PBP.
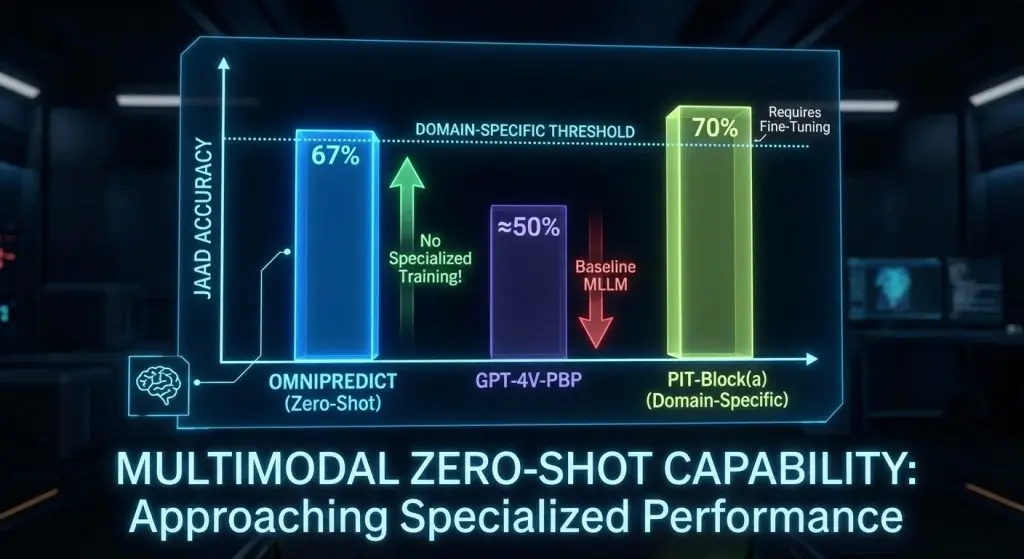
But the assertion needs to be narrowed down. Whereas OmniPredict is better than MLLM baselines, the classic domain-specific models, such as PIT-Block(a), are 70% accurate, a little better. The outstanding difference is that without specific training, OmniPredict attains almost domain-specific performance, which is an extraordinary feat for a general-purpose model.
This “zero-shot” capability, the ability to perform accurately on tasks for which the model has never been explicitly trained, is noteworthy. However, the phrasing requires accuracy: OmniPredict receives no task-specific fine-tuning, but it is evaluated zero-shot on the JAAD dataset and relies on GPT-4o pre-trained on vast quantities of prior data.
The improvement holds across challenging real-world conditions. OmniPredict handles partially occluded pedestrians and unusual behaviors, scenarios where traditional computer vision approaches frequently fail.
The history of autonomous vehicles has involved them working based on reactive principles: detecting an obstacle, processing the data, and performing an action. There are fundamental limitations to this reactive paradigm in high-speed traffic situations, with the time lag between perception and action being the direct predictor of the capacity to avoid accidents.
OmniPredict turns this paradigm upside down to proactive safety. Anticipating the actions of pedestrians, it is possible by forecasting the particular behavior they are most likely to exhibit, instead of merely reacting to movement in the present moment, enabling the autonomous vehicles to identify potential risks before it is possible to condense them into a critical situation. Such a transition is especially useful in tricky situations: a crosswalk with dozens of people, unfavorable conditions of bad weather, or communication with pedestrians whose actions are unpredictable.
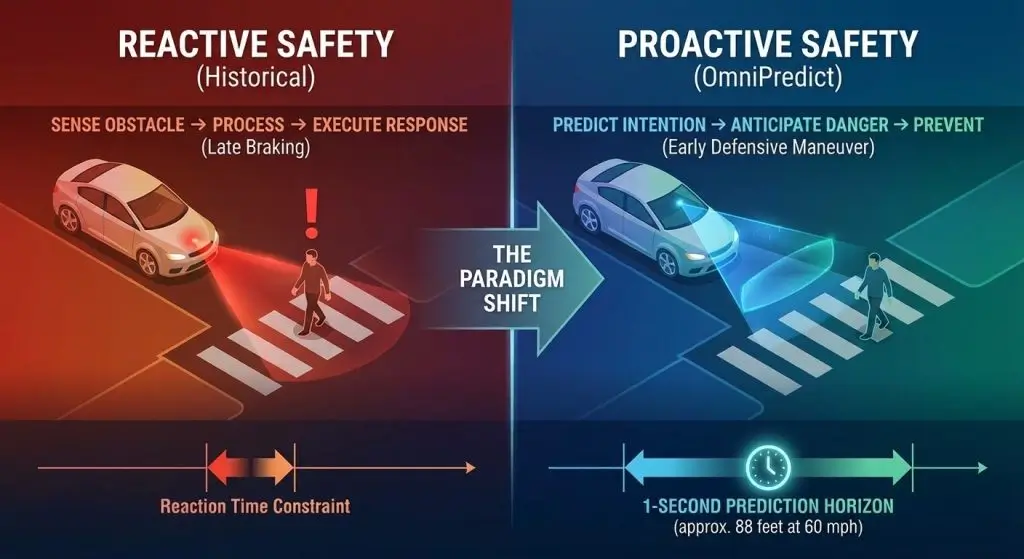
The temporal window, one second, remains crucial. In highway driving at 60 mph, vehicles travel approximately 88 feet per second. A one-second prediction horizon gives the autonomous system time to initiate a defensive maneuver: engaging brakes, changing course or warning human passengers of potential hazards.
The technical innovation behind OmniPredict is based on the non-linguistic concept of multimodal reasoning across types of data. Unlike conventional autonomous driving systems, where camera frames, LiDAR points, and vehicle telemetry were processed through separate analysis pipelines, OmniPredict integrates these modalities in a common reasoning framework.
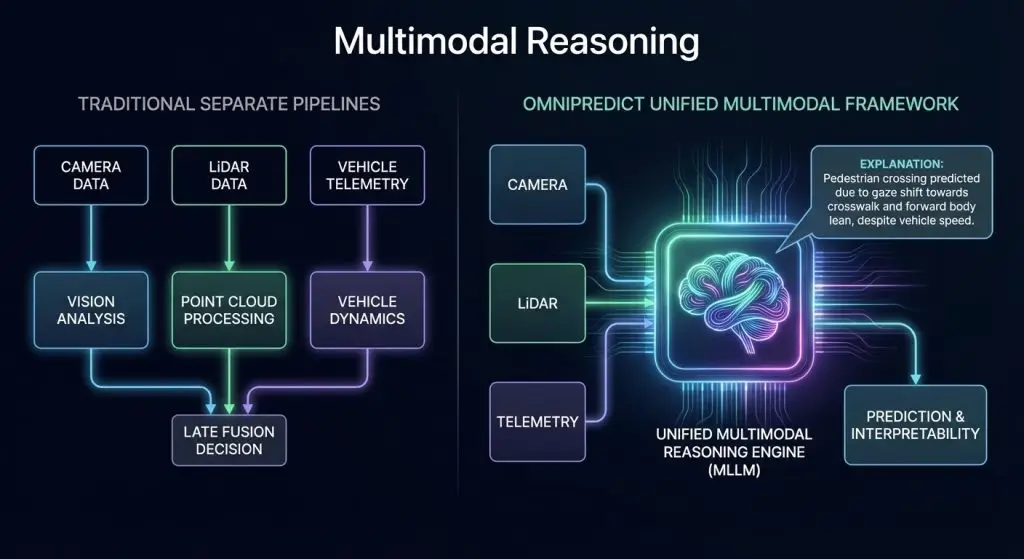
This unified approach offers advantages beyond prediction accuracy.The system can generate natural-language explanations of its predictions, articulating why it believes a pedestrian will cross or remain stationary. This interpretability is increasingly critical for regulatory approval, as governing bodies demand transparent, explainable decision-making in safety-critical applications.
Despite impressive benchmark results, significant obstacles remain before OmniPredict reaches production deployment in commercial autonomous vehicles.
Accuracy Limitations: 67% accuracy means 33% predictions are incorrect, a problematic failure rate in safety-critical systems. A self-driving car relying on behavior predictions with one-in-three error rates would require additional redundancy and conservative decision-making to maintain safety margins.
False Positive/Negative Trade-offs: In behavioral prediction, false negatives carry greater safety risk than false positives; failing to detect crossing when pedestrians will cross is more dangerous than over-predicting. The model’s threshold settings fundamentally determine this balance, yet autonomous vehicles require fail-safe behavior regardless of prediction confidence.
Regulatory and Safety Certification: Regulatory frameworks require transparent, deterministic safety, while large language models produce probabilistic outputs that cannot be easily verified through traditional validation methods. Certifying OmniPredict for production vehicles demands extensive adversarial testing beyond current academic evaluation protocols.
Generalization Across Geographies: The system was trained on North American datasets, capturing JAAD and WiDEVIEW environments. Pedestrian behavior varies significantly across global regions, and crossing norms differ between Tokyo, São Paulo, and Stockholm. Whether OmniPredict generalizes to non-Western urban environments remains untested.
While autonomous vehicle safety motivated OmniPredict development, the system’s behavioral interpretation extends beyond transportation. Potential applications include security monitoring, emergency response operations, and public safety systems.
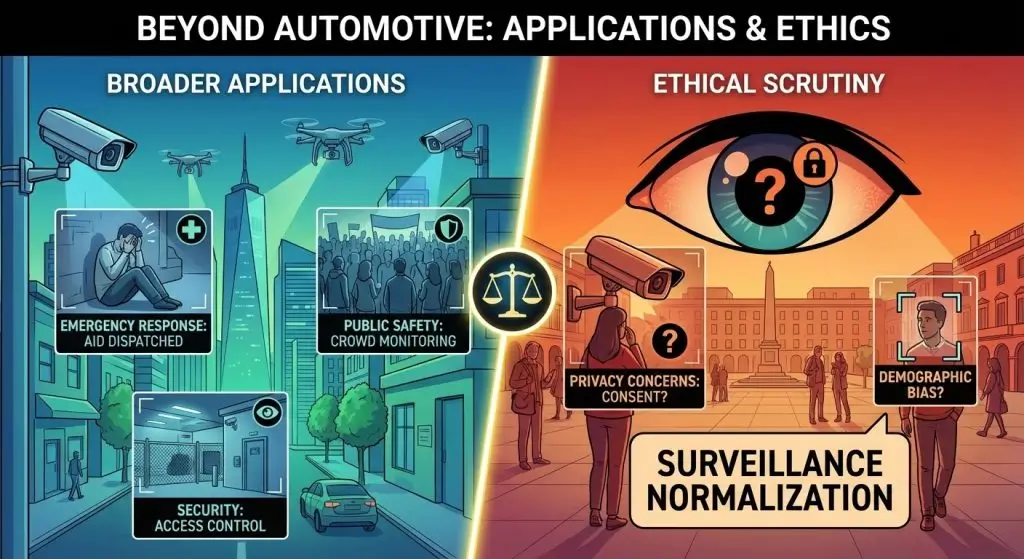
However, such applications warrant ethical scrutiny. Behavioral prediction in public spaces raises privacy concerns, particularly regarding consent, surveillance normalization, and the potential for discriminatory outcomes if the underlying model exhibits demographic bias in its predictions.
OmniPredict is a perfect example of an important trend: large language models show success without task-specific training suggests that multimodal reasoning trained on general data-sets is able to identify generalizable patterns of human behavior applicable to novel contexts.
This “task transfer” capability, where models trained on one objective successfully solve problems in entirely different domains, represents a fundamental advantage of large-scale language models compared to traditional machine learning approaches.
OmniPredict demonstrates that artificial intelligence can move beyond simple perception toward behavioral prediction. By interpreting visual context and temporal patterns, the system attempts to infer pedestrian intention, a capability approximating what humans experience as intuition.
For autonomous vehicles, this capability represents a qualitative shift from reactive safety (detecting obstacles and responding) to proactive safety (anticipating human behavior and preventing accidents before they occur). The 67% zero-shot accuracy, achieved without specialized training, suggests that such systems could eventually be deployed across diverse urban environments.
nsive real-world testing. The prediction of human behavior is essentially always a probability; humans themselves often surprise us with choices that we would not have expected. The journey from promising research to credible, certified systems for autonomous vehicles requires significantly more engineering, testing and validation than current benchmarks show.

Netanel Siboni is a technology leader specializing in AI, cloud, and virtualization. As the founder of Voxfor, he has guided hundreds of projects in hosting, SaaS, and e-commerce with proven results. Connect with Netanel Siboni on LinkedIn to learn more or collaborate on future project.



 Lifetime Hosting
Lifetime Hosting France Lifetime Dedicated Servers
France Lifetime Dedicated Servers Germany Lifetime dedicated servers
Germany Lifetime dedicated servers Lifetime Game Dedicated Servers
Lifetime Game Dedicated Servers Chicago, US
Chicago, US Singapore
Singapore Hong Kong
Hong Kong Seoul, South Korea
Seoul, South Korea Amsterdem, Netherlands
Amsterdem, Netherlands London, UK
London, UK Zurich, Switzerland
Zurich, Switzerland Sydney, Australia
Sydney, Australia DDOS Protection
DDOS Protection Submit Ticket
Submit Ticket Full Management
Full Management Videos and Podcasts
Videos and Podcasts Voxfor Advanced Price Management For WooCommerce
Voxfor Advanced Price Management For WooCommerce Voxfor AI Content Summary
Voxfor AI Content Summary







