
Advancement of artificial intelligence has taken leaps forward in the currently evolving technology, instead of the general-purpose utility, as a more specialized mastery. Although general language models have already proven to be capable of simulating a human conversation on an enormous range of subjects, a domain-specific LLM (large language model) is becoming increasingly common in the enterprise setting. These systems are not just talkers, but they are precision machines, which are either trained or fine-tuned to be specialized in a particular field or zone of subject matter, and can thus perform a niche task more efficiently and with greater accuracy than their general-purpose equivalents. Such development is motivated by the fact that in high-stakes professions like law, medicine, and finance, the generalized knowledge of the internet is not adequate. Thus, there is an inaccuracy that can compromise the effectiveness of the AI systems.

The capacity to integrate industrial-specific data, lexicon, and business peculiarities directly into the structure of the processing is what constitutes a domain-specific large language model. In contrast to general models, which utilize a heterogeneous blend of internet data, such as social media, books and general web content, specialized models use curated datasets of regulatory frameworks, past information of operational activities, and operational guidelines. This is an emphasis that makes sure the model does not simply interpret text, but rather it knows the particular meaning of the wording that the professionals in the field apply when they are referring to it. E.g., the term court has an entirely different color in a legal setting than in a sports or architecture discourse; a domain-specific model is designed in such a way that it intuitively understands the contextual differences.
This specialization is necessitated by the weaknesses that the general models possess, and they tend to dilute their knowledge when dealing with numerous subjects. A general model faced with a specialized query (ex, analyzing a particular clause in a contract, a medical diagnostic report, etc.) has a tendency to guess probabilistically. Although the result might sound authoritative, it might include hallucinations, authoritative yet false statements that are very dangerous in business. This is done through a specialized model that fills the knowledge gaps with high-density data related to the industry.
To visualize the strategic advantage of specialization, it is helpful to contrast the operational characteristics of these two model types across key enterprise dimensions.
| Feature | General-Purpose LLM (e.g., GPT-4) | Domain-Specific LLM (e.g., BloombergGPT) |
| Knowledge Scope | Broad, multi-topic, general internet data | Narrow, high-depth, industry-specific data |
| Linguistic Precision | High for common speech; low for jargon | Expert-level for technical and niche jargon |
| Factual Accuracy | Variable; higher risk of hallucinations | High; grounded in specialized knowledge |
| Resource Intensity | High compute and memory requirements | Optimized; often lower parameter counts |
| Compliance Readiness | Requires external wrappers for regulation | Often has built-in compliance frameworks |
| Primary Use Case | Content generation, general assistance | Legal research, medical diagnosis, risk modeling |
From generalized models to specialized models is not only a technical choice, but a strategic requirement of the organization that works in a controlled environment. Accuracy in these industries would not be compromised. A specialized model in the field of healthcare has the ability to learn the medical terminologies, clinical procedures, and patient care protocols with a certain level of accuracy that the general models fail to do. An example is a model that is trained on the National Institutes of Health PubMed database, which is given with an internal vocabulary and reasoning ability that is specifically designed to support clinical decision making and summarize research.
This final section underscores how specialized AI moves from being a “chatbot” to a functional layer of risk management. In finance, where a single misunderstood term can lead to significant fiscal errors, the shift to specialized models is a move toward safety and efficiency.
In the financial sector, precision translates directly into risk management. Financial institutions utilize domain-specific models for forecasting, transaction reasoning, and sentiment tagging of market news. These models are packed with industry jargon that does not generalize well, such as “equity exposure” or “portfolio drift“. By using models that deeply internalize these concepts, firms can reduce manual errors in complex workflows like claims processing or regulatory reporting.
It is one of the major benefits of domain-specific models: it enables compliance frameworks to be incorporated into the model operational logic. Strict guidelines like HIPAA (Healthcare), FINRA (Finance), and GDPR (Data Privacy) have to be followed in the regulated industries. Whereas the general models tend to store data in the cloud, where there are concerns about data residency and third-party access, specialized models can be executed on-premise. This will enable the sensitive data, including patient health information or corporate proprietary strategy, to be kept in the organization secure environment, which will guarantee complete data sovereignty.
Furthermore, specialized models are often smaller in size (Small Language Models or SLMs), which makes them more efficient to run locally. This efficiency leads to lower latency and predictable costs, as organizations can avoid the per-token billing models common with large-scale cloud APIs. In the context of 2026, when data privacy regulations are expected to intensify, the ability to control the entire model lifecycle, from training data to inference, is a critical competitive advantage.
The process of developing a specialized model involves a spectrum of techniques, ranging from simple prompting to resource-intensive training from scratch. Choosing the right method depends on the organization’s goals, budget, and access to technical expertise.
To those organizations that wish to obtain specialized behavior without having to alter the underlying code of the model, prompt engineering provides the fastest path. This method is done by developing super-specific instructions that direct a generic model to assume a particular personality or speak in a particular language. A user can command a model to always give a short answer in a formal legal language. This, though efficient in the case of simple tasks such as changing the tone of the customer service replies, cannot give the model any new knowledge, merely pointing out the patterns that are already in existence in its training.
RAG has emerged as the default architecture for organizations that need their models to access up-to-date or proprietary information. Instead of forcing the model to memorize every fact during training, RAG connects the model to an external knowledge base, such as a database of internal company documents or the latest case law. When a query is submitted, the system “retrieves” the most relevant snippets from this database and presents them to the model, which then uses its general reasoning skills to “augment” its response.
This approach is highly cost-efficient because it avoids the need for expensive retraining. It also provides a significant layer of explainability, as the model can cite the specific documents used to generate its answer. However, RAG can introduce latency, as the system must perform a search before the model can begin generating text.
Fine-tuning involves taking a pre-trained model and giving it additional training on a curated, domain-specific dataset. This process modifies the model’s internal “weights”, the billions of numerical parameters that define how it processes language. Fine-tuning is ideal when an organization needs the model to adopt a very specific style, format, or professional jargon that it didn’t learn during its initial general training.
Modern techniques such as Low-Rank Adaptation (LoRA) have made fine-tuning accessible to smaller teams. Instead of updating every single parameter in a massive model, which would require supercomputing levels of power, LoRA only updates a small subset of parameters. This makes the process 10 to 100 times more cost-effective while still delivering strong performance gains.
| Method | Best For | Technical Difficulty | Speed to Deploy | Cost |
| Prompt Engineering | Tone and style adjustments | Low | Minutes | Negligible |
| RAG | Facts, private data, real-time updates | Medium | Days | Low to Medium |
| Fine-Tuning | Jargon, reasoning, specific skills | High | Weeks | Medium to High |
| Training Scratch | Proprietary foundations, unique data | Very High | Months | Very High |
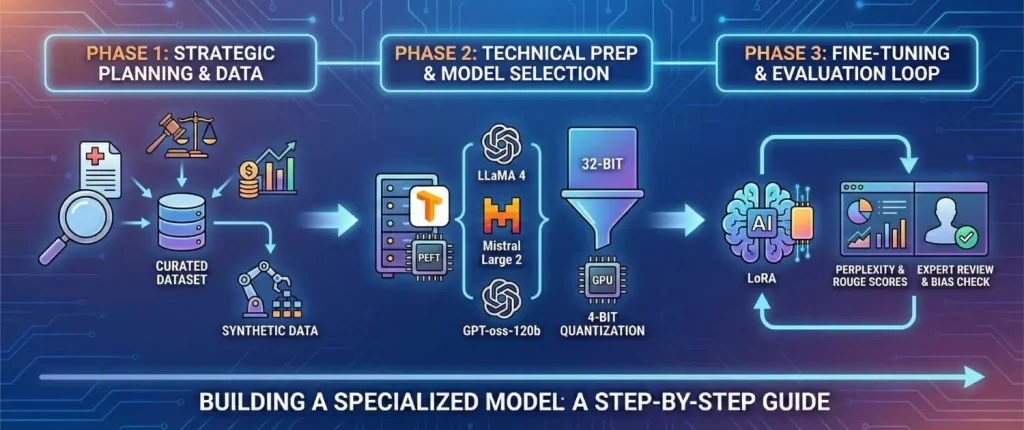
Building a domain-specific model is a structured journey that begins with strategic planning and ends with continuous monitoring. For those new to the field, the following framework provides a roadmap for successful implementation.
The first step is defining the use case with absolute clarity. One must ask: What specific problem is this AI solving? Is it summarizing clinical notes, or is it performing risk assessments for insurance claims? This decision dictates everything from the size of the model to the type of data required.
Data collection is the backbone of the project. A specialized model is only as good as the information it learns from. Practitioners should gather high-quality datasets that represent the diversity of real-world scenarios in their field. In medicine, this might mean medical journals and anonymized clinical records; in law, it might be court decisions and statutes. If real-world data is scarce, teams can use “synthetic data generation” to create additional training materials, though this must be done carefully to avoid introducing errors.
Before training begins, the environment must be prepared. This involves installing essential software libraries such as transformers for model management and peft for parameter-efficient fine-tuning. Teams must also choose a “base model“, a general-purpose foundation that already knows how to speak and write. Popular choices include LLaMA 4, Mistral Large 2, and GPT-oss-120b.
A critical technique during this phase is “quantization.” Because large models require massive amounts of computer memory (GPU memory), quantization reduces the precision of the model’s numbers (e.g., from 32-bit or 16-bit to 8-bit or 4-bit). This allows the model to run on less powerful, more affordable hardware without a significant loss in intelligence.
The curated dataset is fed to the model during the actual fine-tuning process. The system incorporates the new domain knowledge by relying on techniques such as LoRA without the loss of its general language capabilities, a tradeoff required to prevent so-called catastrophic forgetting, where a model becomes specialized to the point of forgetting all of its basic conversational skills.
The last and important step is evaluation. The model should be run against set standards, and above that, human experts in that field. Technical performance is measured using metrics like Perplexity (how predictive the model is of the next word) and ROUGE scores (accuracy of the model at summarizing). Professionals are expected to scrutinize the correctness, tone and any form of bias that could have gone undetected in the learning data.
Explaining the mechanics of AI to business leaders or clients requires moving away from technical jargon and using relatable analogies that illustrate the value of the technology.
Imagine a domain-specific model as a brilliant intern who has read every textbook in your industry but hasn’t yet worked a day in your specific office. They are incredibly efficient and helpful, but they need guidance to understand your company internal rules and quirks. RAG is like giving this intern a key to the company filing cabinet; it allows them to check their facts before they give you an answer, ensuring they don’t make things up based on a half-remembered textbook.
Think of a general LLM as a world-class chef who has tasted thousands of ingredients but doesn’t have a specific menu. Fine-tuning is like giving that chef a specialized training course in a single cuisine, such as high-end pastry making. The chef still knows how to cook everything else, but they now have a deep, intuitive mastery of the specific “recipes” and “weights” of ingredients required for pastries.
Prompt engineering is like giving a general doctor a set of instructions on how to talk to a specific patient. RAG is like giving that doctor a library card to access the latest medical journals during a consultation. Fine-tuning is like sending that doctor back to medical school for a residency in neurosurgery, they have deeply internalized the specialized knowledge so that it becomes a part of how they think and reason.
People are starting to ask AI tools like ChatGPT and Gemini for answers instead of just typing searches into Google. This is changing how we do online marketing. The new goal isn’t just to show up in a list of search results; it is to make sure your brand is the trusted source that the AI actually uses to answer the user’s question.
The concept of traditional SEO was commonly connected with the idea of keyword density, whereas AI-based models start placing emphasis on semantic relevance and context. The search behavior in the modern world is shifting towards short, fragmented keywords to long and conversational prompting. As an illustration, a user would not type in the search query of SEO tips, but could say, “What is the best method of increasing the visibility of my website in the results of AI-generated searches in the free search?” Content strategy has to scale to meet these questions with detailed answers written in a natural language.
To rank in an AI response, a brand must focus on “Entity Optimization“, making it clear to the AI what the brand is, what it does, and why it is an authority. AI platforms tend to cite content that is structured and concise, such as how-to guides, FAQs, and comparison tables. Furthermore, mentions on authoritative platforms like Reddit, Quora, and niche industry forums act as powerful trust signals that AI models use to verify a brand’s credibility.
| SEO Dimension | Traditional Search (Google) | AI Search (GEO) |
| Search Query | Short keywords (e.g., “tax AI”) | Full prompts (e.g., “How do I use AI for tax?”) |
| Ranking Signal | Backlinks and page speed | Accuracy, authority, and citations |
| Content Format | Long-form articles | Structured Q&A, lists, and tables |
| Success Metric | CTR and Keyword Ranking | AI Visibility and Share of Voice |
| Primary Tool | Google Search Console | Prompt tracking and brand mention monitoring |
The adoption of specialized models has already produced tangible results across diverse sectors, proving that the move away from general-purpose AI is a practical, value-driven decision.
The global giants in the manufacturing industry are adopting specialized models to streamline the supply chain, which encompasses hundreds of vendors and real-time data on logistics. An example of this is the use of an AI-driven analytics system that is installed by ArcelorMittal Nippon Steel and collects fragmented data on 230 suppliers. This specialization made it possible to make decisions 80 percent faster and reduced planning by 65 percent. Likewise, General Electric also applies its Predix to access maintenance reports and detect warning signals in industrial machinery before they result in expensive failures.
Energy companies deal with huge amounts of paperwork, like drilling reports and environmental studies. Companies like ExxonMobil now use specialized AI to read through thousands of scientific papers automatically. This helps them quickly spot new technologies, such as carbon capture or renewable energy methods, so that they can stay ahead of the competition.
Whereas general language models usually fail at complex maths, specialized models such as MathGPT have realized state-of-the-art performance. With explicit reasoning and a chain of thought, these models are capable of finding solutions to problems in mathematics at competition levels with accuracy exceeding that of generic models such as GPT-4. Educational tools and scientific study area is very important, and the specialized field also requires such a critical level of specialization where accuracy in formulas and logic is the most important aspect.
As specialized models become more integrated into daily operations, the focus on governance and risk management has intensified. Because these models are used in high-stakes environments, the consequences of bias or error are significant.
Domain-specific models are only as fair as the data used to train them. If an AI used for credit scoring is trained on historical data that contains human bias against certain demographics, the model will likely replicate those unfair patterns. Responsible AI practices now require “fairness audits” and the use of balanced, representative datasets to ensure that specialized intelligence does not lead to discriminatory outcomes.
Looking toward 2026, the trend is moving toward “Agentic AI“, models that don’t just provide information but take action on behalf of the user. These agents, powered by domain-specific LLMs, can sit inside enterprise tools like CRMs or supply chain management systems. They can autonomously draft proposals using real-time pricing, flag compliance risks in change requests, or even coordinate between different departments to solve complex logistical bottlenecks.
Governments are finally setting rules for AI. The EU AI Act, which started in late 2024, requires companies to be transparent and keep users safe. This means businesses must now be able to explain exactly how their AI made a decision, you can’t just say “the computer did it.” Specialized models are the best solution here because they run on your own servers. This gives you full control over the data and the logic, making it much easier to prove you are following the law.
AI is growing up. Companies are moving past the hype of “do-it-all” bots and starting to build “expert” tools that solve real problems. This shift is all about accuracy and saving money. Whether you connect the AI to your own data (RAG) or train it on specific skills (fine-tuning), these specialized models are simply more reliable than general ones.
For professionals, the implementation of these models requires a balanced approach, combining the best of existing foundation models with the unique proprietary data that makes their business unique. By following a structured development lifecycle and prioritizing data quality, enterprises can build AI systems that not only speak the language of their industry but also understand the profound meaning and implications of every word. As we move into an era of agentic, multimodal, and highly regulated AI, the ability to create and govern domain-specific intelligence will be the defining factor of success in the digital economy.

Hassan Tahir wrote this article, drawing on his experience to clarify WordPress concepts and enhance developer understanding. Through his work, he aims to help both beginners and professionals refine their skills and tackle WordPress projects with greater confidence.


 Lifetime Hosting
Lifetime Hosting France Lifetime Dedicated Servers
France Lifetime Dedicated Servers Germany Lifetime dedicated servers
Germany Lifetime dedicated servers Lifetime Game Dedicated Servers
Lifetime Game Dedicated Servers Chicago, US
Chicago, US Singapore
Singapore Hong Kong
Hong Kong Seoul, South Korea
Seoul, South Korea Amsterdem, Netherlands
Amsterdem, Netherlands London, UK
London, UK Zurich, Switzerland
Zurich, Switzerland Sydney, Australia
Sydney, Australia DDOS Protection
DDOS Protection Submit Ticket
Submit Ticket Full Management
Full Management Videos and Podcasts
Videos and Podcasts Voxfor Advanced Price Management For WooCommerce
Voxfor Advanced Price Management For WooCommerce Voxfor AI Content Summary
Voxfor AI Content Summary







