OpenAI launched GPT-5.3 Codex on February 5, 2026, the same day Anthropic dropped Claude Opus 4.6. Both companies timed their releases to dominate the conversation around frontier AI coding models. But the competitive field is wider than a two-horse race. Google Gemini 3 Pro, xAI’s Grok 4.1, and Moonshot AI’s Kimi K2.5 each bring unique strengths that reshape the landscape. This is a full breakdown of what each model does best, where it falls short, and which one fits your workflow.
GPT-5.3 Codex merges the frontier coding performance of GPT-5.2-Codex with the reasoning and professional knowledge of GPT-5.2 into a single, unified model that runs 25% faster. OpenAI positions it as a full computer-use agent, not just a code autocomplete tool, but a system that can debug, deploy, monitor, write PRDs, edit copy, run tests, and analyze metrics across terminals, IDEs, browsers, and desktop apps.
The most striking detail about this release: early versions of GPT-5.3 Codex were used to help train and deploy the final model itself. The Codex team used earlier iterations to debug the training run, manage deployment, diagnose evaluations, and summarize large-scale logs, a closed feedback loop where the agent improves its own infrastructure.
GPT-5.3 Codex is also the first OpenAI model classified as “High capability” for cybersecurity tasks and the first directly trained to identify software vulnerabilities. OpenAI has committed $10M in API credits to accelerate cyber defense, especially for open-source software and critical infrastructure.
Claude Opus 4.6 is Anthropic answer to the agentic AI era. It features a 1M token context window, hybrid reasoning that allows instant or extended thinking, and a new Agent Teams feature that allows parallel multi-agent coordination.
Agent Teams is the standout innovation. Instead of one agent working sequentially, Opus 4.6 splits work across multiple agents, each owning its piece and coordinating directly with the others. In one documented case, 16 agents built a 100,000-line compiler working in parallel. Anthropic Head of Product, Scott White, compared the feature to “having a talented team of humans working for you.”
In cybersecurity, Opus 4.6 produced the best results in 38 out of 40 blind investigations against Claude 4.5 models, each running end-to-end on the same agentic harness with up to 9 subagents and 100+ tool calls. It also scored 90.2% on BigLaw Bench, the highest of any Claude model for legal reasoning.
Gemini 3 Pro, released in November 2025, dominates in reasoning, multimodal understanding, and long-horizon planning. It scores 91.9% on GPQA Diamond for PhD-level science questions, nearly 4 points above GPT-5.1. On ARC-AGI-2, its 31.1% (45.1% with Deep Think) represents a massive jump from Gemini 2.5 Pro’s 4.9%.
Where Gemini 3 Pro truly separates itself is multimodal reasoning. Its 81.0% on MMMU-Pro and 87.6% on Video-MMMU show it can process and reason across images and video simultaneously at a level no other model matches. It also achieves 72.1% on SimpleQA Verified for factual accuracy, the highest score in the field.
For coding, Gemini 3 Pro achieved 74% on SWE-Bench Verified with a minimal agent (no prompt tuning), placing it at the top of the independent leaderboard at the time. It holds a commanding 2,439 Elo on LiveCodeBench Pro, nearly 200 points above GPT-5.1. However, its Terminal-Bench 2.0 score of 54.2% lags significantly behind GPT-5.3 Codex’s 77.3%.
The Vending-Bench 2 results may be the most telling real-world signal: Gemini 3 Pro mean net worth in the year-long business simulation was 272% higher than GPT-5.1, indicating exceptional long-horizon planning and decision consistency.
Grok 4.1, released in November 2025, brings several notable improvements over Grok 4: up to 65% fewer hallucinations, 30-40% faster responses, native multimodal vision, and a 2M token context window on the Grok 4.1 Fast variant. On the LMSYS Arena, Grok 4.1 in Thinking mode reached 1,483 Elo.
The Grok 4 base model scored 58.6% on SWE-bench in independent testing, a significant improvement over Grok 3 (16.6% higher) but still trailing the top-tier models. Grok’s real competitive edge is its deep integration with the X platform and Tesla vehicles, plus its emotional intelligence and creative writing capabilities.
xAI has confirmed that Grok 5 will arrive in Q1 2026 with 6 trillion parameters, double the size of Grok 3 and 4. The company has also expanded into government AI with a $200 million Department of Defense contract.
Moonshot AI Kimi K2.5, released in January 2026, is arguably the biggest surprise in this field. Built on a Mixture-of-Experts (MoE) architecture with 1 trillion total parameters but only 32 billion active per token, it delivers frontier-level performance at a fraction of the cost.
The Agent Swarm technology is Kimi K2.5 headline feature. It coordinates up to 100 specialized AI agents working simultaneously, cutting execution time by 4.5x on parallelizable tasks. On BrowseComp, Agent Swarm mode achieves 78.4% compared to 60.6% in standard agent mode. Kimi K2.5 also achieved 50.2% on Humanity’s Last Exam (with tools), the highest reported score among these models.
On coding benchmarks, Kimi K2.5 scores 76.8% on SWE-Bench Verified and 85.0% on LiveCodeBench, placing it firmly in the top tier. Its native multimodal training enables direct vision-to-code workflows: submit a UI mockup or video walkthrough, and K2.5 generates production-ready React or HTML implementations.
The pricing is the real kicker: $0.60 per million input tokens and $2.50 per million output tokens, approximately 76% cheaper than Claude Opus 4.5 and 44% cheaper than GPT-5.2. And it’s open-source under a Modified MIT license, meaning organizations can download weights from Hugging Face and deploy on private infrastructure.
| Benchmark | GPT-5.3 Codex | Claude Opus 4.6 | Gemini 3 Pro | Grok 4.1 | Kimi K2.5 |
| SWE-Bench Pro/Verified | 56.8% (Pro) | Leading | 74–76.2% | 58.6% (Grok 4) | 76.8% |
| Terminal-Bench 2.0 | 77.3% | 65.4% | 54.2% | N/A | N/A |
| OSWorld | 64.7% | 72.7% | N/A | N/A | N/A |
| GPQA Diamond | N/A | N/A | 91.9% | N/A | 87.6% |
| AIME 2025 | N/A | N/A | 100% (w/ tools) | N/A | 96.1% |
| MMMU-Pro | N/A | N/A | 81.0% | N/A | 78.5% |
| BrowseComp | N/A | N/A | N/A | N/A | 78.4% (Swarm) |
| HLE (w/ tools) | N/A | N/A | 37.5% | N/A | 50.2% |
| Cyber CTF | 77.6% | Strong | N/A | N/A | N/A |
| LiveCodeBench Pro (Elo) | N/A | N/A | 2,439 | N/A | 85.0% (pass@1) |
| Feature | GPT-5.3 Codex | Claude Opus 4.6 | Gemini 3 Pro | Grok 4.1 Fast | Kimi K2.5 |
| Context window | ~256K | 1M | 1M | 2M | 256K |
| Max output | 32K | 128K | 64K | N/A | 262K |
| Input pricing (/M tokens) | $6 | $5 | Competitive | $300/mo (SuperGrok) | $0.60 |
| Output pricing (/M tokens) | $30 | $25 | N/A | Subscription-based | $2.50 |
| Open source | No | No | No | No | Yes (MIT) |
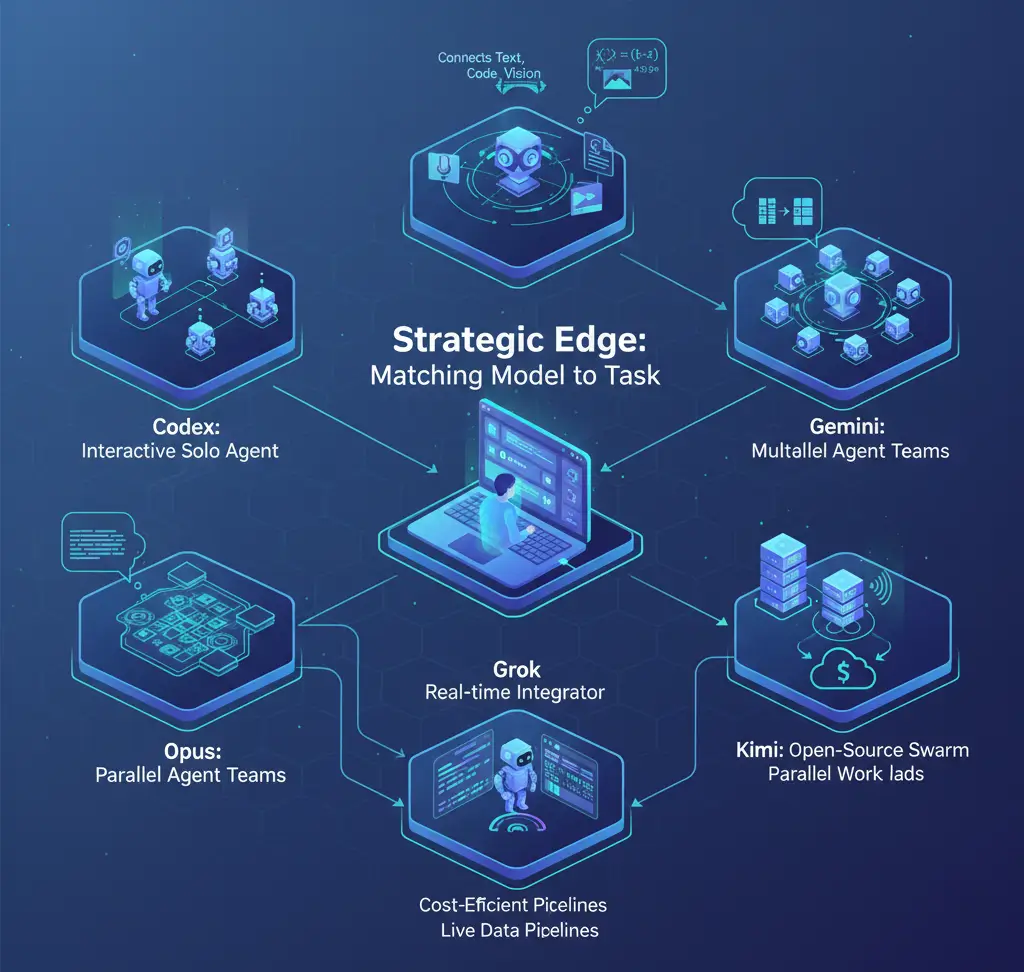
Each model takes a fundamentally different approach to agentic AI:
Security is emerging as a key differentiator. GPT-5.3 Codex is the only model directly trained to find software vulnerabilities, with a “High capability” classification under OpenAI’s Preparedness Framework. OpenAI is expanding Aardvark, its security research agent, and partnered with open-source maintainers to scan widely used projects — a researcher already used Codex to find vulnerabilities in Next.js.
Claude Opus 4.6 demonstrated dominant security performance in blind testing: 38 of 40 cybersecurity investigations were won against previous Claude models, each running complex multi-agent harnesses.
Neither Gemini 3 Pro, Grok 4.1, nor Kimi K2.5 has marketed comparable cybersecurity-specific capabilities, though Gemini 3 Pro’s superior factual accuracy (72.1% SimpleQA Verified) reduces the risk of hallucinated security findings.
Choose GPT-5.3 Codex for fast interactive terminal-based coding, cybersecurity vulnerability research, rapid prototyping, and workflows where a single powerful agent needs to plan and execute autonomously.
Choose Claude Opus 4.6 for large codebase analysis (1M context), multi-agent parallel workflows, enterprise knowledge work, legal reasoning, and security audits that span multiple files.
Choose Gemini 3 Pro for multimodal reasoning (images + video), algorithmic problem-solving, scientific research, long-horizon planning, and multilingual applications across 100+ languages.
Choose Grok 4.1 for real-time social media and news integration, massive document processing (2M context), creative writing, and workflows deeply tied to the X/Twitter ecosystem.
Choose Kimi K2.5 for cost-sensitive deployments, parallel Agent Swarm workflows, vision-to-code development, open-source self-hosting, and scenarios where running inference on your own infrastructure matters.
February 2026 marks the moment AI coding moved from “impressive demo” to “genuine multi-vendor competition.” Five fundamentally different architectures, solo computer-use agent (Codex), parallel agent teams (Opus), multimodal reasoner (Gemini), real-time integrator (Grok), and open-source swarm orchestrator (Kimi)—now compete across overlapping but distinct use cases.
The practical takeaway for developers and teams: no single model dominates every dimension. The most effective strategy is matching the model to the task profile. Use Codex for tight interactive loops. Deploy Opus for complex multi-agent orchestration. Leverage Gemini for multimodal reasoning. Tap Grok for real-time data. Run Kimi for cost-efficient parallel workloads on your own hardware. Tools like Continue.dev and Cursor already make switching between models seamless.
The race is no longer about which model is “best.” It’s about which combination of models gives your team the strongest competitive edge across the full spectrum of work that AI can now do.

Netanel Siboni is a technology leader specializing in AI, cloud, and virtualization. As the founder of Voxfor, he has guided hundreds of projects in hosting, SaaS, and e-commerce with proven results. Connect with Netanel Siboni on LinkedIn to learn more or collaborate on future project.


 Lifetime Hosting
Lifetime Hosting France Lifetime Dedicated Servers
France Lifetime Dedicated Servers Germany Lifetime dedicated servers
Germany Lifetime dedicated servers Lifetime Game Dedicated Servers
Lifetime Game Dedicated Servers Chicago, US
Chicago, US Singapore
Singapore Hong Kong
Hong Kong Seoul, South Korea
Seoul, South Korea Amsterdem, Netherlands
Amsterdem, Netherlands London, UK
London, UK Zurich, Switzerland
Zurich, Switzerland Sydney, Australia
Sydney, Australia DDOS Protection
DDOS Protection Submit Ticket
Submit Ticket Full Management
Full Management Videos and Podcasts
Videos and Podcasts Voxfor Advanced Price Management For WooCommerce
Voxfor Advanced Price Management For WooCommerce Voxfor AI Content Summary
Voxfor AI Content Summary







