
A video AI breakthrough with the release of ByteDance Seedance 2.0 in early 2026 can be described as dramatic. Text-to-video models have long been based on the black-box paradigm: you input a written prompt, and hope the output looks like your vision. Seedance 2.0 flips that script. It presents a multimodal All-Round Reference system allowing creators to add up to 12 reference files, images, video clips, and audio tracks, and explicitly indicates all the elements of the scene. Effectively, you now have a virtual director console: present the AI with what shots, characters, and sounds you would like to see, and it complies.
This frame is an example of the outcomes: lighting, character, and motion are all demonstrated in a consistent manner. Creators do not use ambiguity in text prompts; instead, they ground the AI imagination in concrete media. In Seedance 2.0, you could post a portrait of an actor, a camera shot, and a beat of music and label it as use @Image1 as the hero, replicate @Video1 pan, and time action to @Audio1. The model then makes sense of the references and integrates them into one consistent video. The output produced is aligned with the desired cinematic effect of the creator, not something generated through random generative gambits.
Seedance 2.0 unifies text, images, video, and audio into one generation architecture. Official documentation confirms it supports “up to 9 images, up to 3 videos (total ≤15s), up to 3 audio files (≤15s) and natural language instructions, for a total of 12 files.”
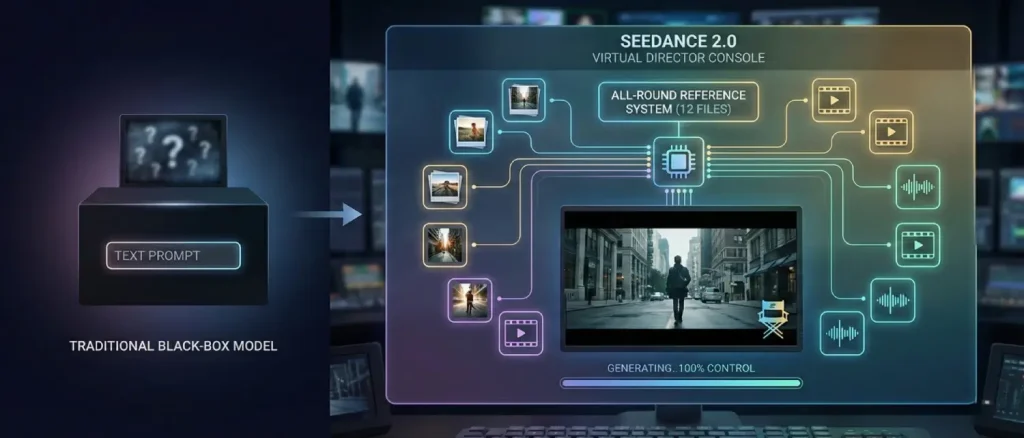
Put simply: you can scatter your 12 slots across modalities however you like – for example, 8 images + 2 videos + 2 audio, or 4 images + 3 videos + 5 audio, etc. This flexible limit encourages creators to use only the most relevant references, which in turn yields cleaner, more predictable results. Indeed, Seedance designers tout the 12-file cap as “a feature, not a constraint,” pushing users toward high-quality, high-signal inputs.
By comparison, most competing video models remain text-centric or single-reference. For example, Google Sora and Meta Make-A-Video only accept text or at most one image, while others like Runway Gen-3 allow image + text but no video or audio. Seedance 2.0 stands alone: multimodal inputs up to 12 files, versus text-only or image-plus-text for others.
As one tech guide summarizes, Seedance is now built to handle “any combination of visual, video, and audio inputs” in one generation. This multimodal input is the heart of its All-Round Reference system. It means instead of writing “a dancer doing a pirouette in a ballroom,” you can actually show the model a ballroom photo, a dancer’s outfit image, a clip of a pirouette, and a classical music excerpt. The model will use each reference appropriately, producing exactly what you showed it — a controlled choreography with the correct setting and timing.
The key to Seedance creative control is its @Tag referencing system. After uploading your images, clips, and audio, you refer to each in the prompt by an @prefix and an ID such as @Image1, @Video1, or @Audio1. You then describe what to do with that reference, giving the model explicit directional instructions.
“Use @Image1 as the hero’s look, @Image2 as background,
follow @Video1 camera movement, and sync actions to @Audio1 beat."This specifically informs the model: Image1 is used to get the face and costume; Image2 is used to get the scene layout; Video1 is used to get the motion choreography; and Audio1 is used to get the timing. The AI processes every reference with a special encoder (visual patch tokens in the case of images, spatiotemporal tokens in the case of video, spectrogram in the case of audio) and finally produces a single latent representation. Since all the inputs are different and marked, it is able to maintain each of the elements without confusion.
The practical outcome is like having a director’s storyboard. For example, the model can “tell the difference between a character reference and a style reference,” as one user guide notes. You could upload two photos of the same person (frontal and profile) and say, “@Image1 is the first shot, @Image2 is the last shot; maintain the same face in both.” Seedance 2.0 will keep that face and identity consistent across the generated sequence. Another prompt might say, “Use @Video1 for all camera pans and @Image3 for the actor’s outfit.” The engine will latch onto those cues precisely, dramatically reducing the “morphing” errors common in earlier AI videos.
Tech reviewers have confirmed this modular flexibility. Researchers in hands-on tests discovered they could transform one reference such as changing the motion clip, and only that part of the output would change; they could not alter the face of the character, her clothes, or the background since those references had not been modified.
Such modular control has never been seen in text-to-video. You do not have to rewrite a complete prompt to correct a single problem, but simply replace or modify the corresponding reference. The others act as anchors, maintaining uniformity. One tester captured it clearly: it is possible to iterate on one dimension of video without losing progress on all the others. This accelerates creativity by a large margin.
With the All-Round Reference system, Seedance 2.0 behaves more like a film editor than a random image generator. Every key creative decision can be locked down. For example:
Combining these lets creators “direct” their scene. In one tutorial, a user called the result “the model respects your files, it’s built for ‘reference-to-video’.” Another guide points out that this shift means creators think less about writing the perfect prompt and more about building a brief with references that remove ambiguity.
In practice, people use it to clone viral videos or cinematic sequences: show the AI a popular clip, provide an actor or character image, and say, “apply this look and background to that motion.” Seedance 2.0 will output a new video with your subject performing that choreography, all guided by the provided inputs.
From a technical standpoint, the All-Round Reference system improves every major shortcoming of prior models. By anchoring on input assets:
This is prior to the release of Seedance 2.0, where the workflow of AI video was frequently text-centric. Users detailed scenes and then wordy prompts were tweaked over hours. The outcomes were unstable: one word alteration could change the entire clip without any foreseeing.
By comparison, Seedance 2.0 uses a reference-based approach, making it feel more like a precision instrument than a slot machine. Key differences include:
Simply put, Seedance 2.0 is more like a professional video editing application with AI support than a black box to play with. One of the reviews refers to it as stepping away from guessing with AI to accurate guidance. Another adds that the UI has been transformed into something closer to a video editor, just drag in references and type a shot list in text, rather than writing a novel-length prompt. It represents a paradigm change in the interaction between creators and AI.
The All-Round Reference system opens up new possibilities across industries. Here are some key scenarios where creators are already experimenting with Seedance 2.0:
The common theme in these scenarios is efficiency and fidelity. Whether one is on a shoestring indie film budget or part of a high-volume marketing team, Seedance 2.0 offers a way to get professional-looking footage with minimal overhead.
Creators report that even tasks like adding product logos or brand colors have never been easier: simply include the design as an image reference, and the AI handles the rest with pixel-level accuracy. Another user quoted on the website said they “10x’d” their content output by referencing templates and remixing them with their own style.
Even with great tools, technique matters. Here are practical tips distilled from early adopters, tutorials, and community guides:
0-4s: Wide shot city street. @Image1 actor walks toward the camera. @Audio1 sounds of traffic.
5-9s: Close-up on the actor's face. Focus on expression. Maintain @Image1 identity.
10-15s: Tracking shot pulling back to show city skyline.This approach forces the AI to plan shots sequentially and maintain continuity. In fact, the EveryLab prompt structure was described as “more predictable than anything from unstructured prompts.” Use it especially for narrative or multi-shot work.
Experimentation is necessary in every situation. Conveniently, many users begin with a very simple setup: one image + one video + possibly one audio + minimal text. Once you have a functional foundation, you can gradually become more complex.
Over time, you will understand which modality affects what and how to word prompts for maximum effect. The core mindset is this: think of the AI as a cooperative partner, and it will produce aligned, high-quality output.
It helps to contextualize Seedance 2.0 by comparing it with prior tools and models:
In summary, Seedance 2.0 redefines the AI video category. Instead of fitting features into an existing mold, it creates a new one: “reference-first” video generation. Reviewers consistently remark that it feels like a professional video creation platform, not just a demo tool. One even noted that the UI now “feels like a video editor” rather than an AI lab instrument.
By directly enabling director-style workflows such as shot-list prompts, reference uploads, and segment extensions, Seedance elevates AI from a novelty gadget to a practical production tool.
Seedance 2.0 is already making waves. Early adopters span from hobbyists to professionals:
These stories underline a common truth: the more seeds (references) you provide, the less the AI has to “imagine.” What’s revolutionary is that now every input can be a seed.
This concept explains why ByteDance says creators can “transform ideas into visuals with full control.” It also sheds light on the stock market reaction reported in tech media, where investors see Seedance 2.0 as making high-quality video generation both cheaper and faster than traditional production.
From a creative standpoint, it positions the AI as a versatile partner rather than a wild card.
Seedance 2.0 has ushered in a new paradigm: reference-first AI video generation. By allowing up to 12 mixed-media inputs with clear tagging, it transforms vague prompts into detailed instructions. Creators gain the power to dictate casting, choreography, cinematography, and sound, all within a single system. In doing so, the AI steps out of the black box and into the director’s chair.
Gone are the days of endlessly tweaking text prompts and hoping for the best. Now you show the AI exactly what you want and specify how each element should be used. The result is not random art, but reliable, professional-looking video that follows your creative vision. Whether building an ad campaign, a film storyboard, or a viral video, the All-Round Reference system gives creators direct control, elevating AI from a novelty to a true production tool.
As one test put it: “Seedance replaced luck with logic.” With that shift, the era of “AI video as a guessing game” is coming to an end. We now have an AI video model that listens, follows instructions, and delivers, one that, in ByteDance’s words, allows creators to “be true directors” of their digital content.

Hassan Tahir wrote this article, drawing on his experience to clarify WordPress concepts and enhance developer understanding. Through his work, he aims to help both beginners and professionals refine their skills and tackle WordPress projects with greater confidence.



 Lifetime Hosting
Lifetime Hosting France Lifetime Dedicated Servers
France Lifetime Dedicated Servers Germany Lifetime dedicated servers
Germany Lifetime dedicated servers Lifetime Game Dedicated Servers
Lifetime Game Dedicated Servers Chicago, US
Chicago, US Singapore
Singapore Hong Kong
Hong Kong Seoul, South Korea
Seoul, South Korea Amsterdem, Netherlands
Amsterdem, Netherlands London, UK
London, UK Zurich, Switzerland
Zurich, Switzerland Sydney, Australia
Sydney, Australia DDOS Protection
DDOS Protection Submit Ticket
Submit Ticket Full Management
Full Management Videos and Podcasts
Videos and Podcasts Voxfor Advanced Price Management For WooCommerce
Voxfor Advanced Price Management For WooCommerce Voxfor AI Content Summary
Voxfor AI Content Summary







